
La norme d’exclusion des robots a été élaborée en 1994 afin que les propriétaires de sites Web puissent indiquer aux moteurs de recherche comment explorer leur site.
Placer un fichier robots.txt à la racine de votre domaine vous permet d’empêcher les moteurs de recherche d’indexer des fichiers et des répertoires sensibles. Par exemple, vous pouvez empêcher un moteur de recherche de parcourir votre dossier d’images ou d’indexer un fichier PDF situé dans un dossier secret.
Les principales recherches suivront les règles définies. Néanmoins, les robots des logiciels malveillants et les mauvais moteurs de recherche peuvent ne pas respecter vos règles et indexer ce qu’ils veulent.
Découvrez comment créer et modifier un fichier robots.txt !
Qu’est-ce que le robots.txt ? Un fichier robots.txt peut être créé en quelques secondes. Tout ce que vous avez à faire est d’ouvrir un éditeur de texte et enregistrer un fichier vierge sous le nom de robots.txt.
Une fois que vous avez ajouté quelques règles au fichier, enregistrez le fichier et importez-le à la racine de votre domaine, à savoir www.votresite.fr/robots.txt. Veillez à placer le fichier robots.txt à la racine de votre domaine, même si WordPress est installé dans un sous-répertoire.
Nous recommandons des autorisations fichiers 644 pour le robots.txt. La plupart des hébergements configurent ce fichier avec ces autorisations après le téléchargement du fichier. Vous devriez également considérer les plugins WordPress qui vous permettent de modifier le fichier robots.txt directement dans la zone d’administration de WordPress. Cela vous évitera d’avoir à retélécharger votre fichier robots.txt par FTP à chaque fois que vous le modifiez.
Les moteurs de recherche rechercheront un fichier robots.txt à la racine de votre domaine lorsqu’ils exploreront votre site Web. Veuillez noter qu’un fichier robots.txt distinct devra être configuré pour chaque sous-domaine et pour d’autres protocoles tels que https://www.votresite.com.
Il est assez facile de comprendre la norme d’exclusion des robots, car il n’y a que quelques règles à apprendre. Ces règles sont généralement appelées directives.
Les deux principales directives de la norme sont les suivantes
Un astérisque (*) peut être utilisé comme “joker” avec User-agent pour faire référence à tous les moteurs de recherche. Par exemple, vous pouvez ajouter le texte suivant au fichier robots.txt de votre site Web pour empêcher les moteurs de recherche d’explorer l’ensemble de votre site.

La directive ci-dessus est utile si vous développez un nouveau site Web et que vous ne voulez pas que les moteurs de recherche indexent votre site incomplet.
Certains sites Web utilisent la directive disallow sans le slash pour indiquer qu’un site Web peut être exploré. Cela permet aux moteurs de recherche d’avoir un accès complet à votre site Web.
Le code indique que tous les moteurs de recherche peuvent explorer votre site Web. Il est inutile de saisir uniquement ce code dans votre fichier robots.txt, car les moteurs de recherche exploreront votre site Web même si vous ne définissez pas. Toutefois, il peut être utilisé à la fin d’un fichier robots.txt pour faire référence à tous les autres User-agent.
Vous pouvez voir dans l’exemple ci-dessous que nous avons spécifié le dossier des images en utilisant /images/ et non www.votresite.fr/images/. Cela s’explique par le fait que le fichier robots.txt utilise des chemins relatifs et non des chemins URL absolus. Le slash/la barre oblique (/) fait référence à la racine d’un domaine et applique donc les règles à l’ensemble de votre site Web. Les chemins d’accès sont sensibles à la casse, veillez donc à utiliser la bonne casse lorsque vous définissez des fichiers, des pages et des répertoires.

Afin de définir des directives pour des moteurs de recherche spécifiques, vous devez connaître le nom du crawler du moteur de recherche (alias l’User agent). Googlebot-Image, par exemple, définira des règles pour le moteur de recherche Google Images.

Notez que si vous définissez des User agent spécifiques, il est important de les énumérer au début de votre fichier robots.txt. Vous pouvez ensuite utiliser User-agent : * à la fin pour faire correspondre tous les User agent qui n’ont pas été définis explicitement.
Ce ne sont pas toujours les moteurs de recherche qui explorent votre site Web ; c’est pourquoi les termes User agent, robot ou bot sont souvent utilisés à la place du terme crawler. De nombreux robots Internet peuvent potentiellement explorer votre site Web. Le site Web Bots vs Browsers répertorie actuellement environ 1,4 million de User agent dans sa base de données et ce nombre continue d’augmenter chaque jour. La liste contient des navigateurs, des consoles de jeu, des systèmes d’exploitation, des bots, etc.
Bots vs Browsers est une référence très utile pour vérifier les détails d’un User agent dont vous n’avez jamais entendu parler auparavant. Vous pouvez également consulter User-Agents.org et User Agent String.
Rassurez-vous, nul besoin de vous souvenir de tous les User agent et les robots d’indexation de moteurs de recherche. Il vous suffit de connaître le nom des robots et des crawlers auxquels vous souhaitez appliquer des règles spécifiques. Pour le reste, utilisez le caractère générique * pour appliquer des règles à tous les moteurs de recherche.
Voici quelques robots de moteurs de recherche courants que vous pouvez utiliser :
Veuillez également noter que Google Analytics n’affiche pas de façon native le trafic d’exploration des moteurs de recherche car les robots des moteurs de recherche n’activent pas Javascript.
Cependant, Google Analytics peut être configuré pour afficher des informations sur les robots des moteurs de recherche qui explorent votre site Web. Les analyseurs de fichiers journaux fournis par la plupart des sociétés d’hébergement, tels que Webalizer et AWStats, affichent des informations sur les robots d’exploration.
Consultez ces statistiques pour votre site Web afin d’avoir une meilleure idée de la façon dont les moteurs de recherche interagissent avec le contenu de votre site.
User-agent et Disallow sont supportés par tous les crawlers, mais quelques directives supplémentaires sont disponibles. Celles-ci sont dites non standard car elles ne sont pas prises en charge par tous les robots d’exploration. Toutefois, dans la pratique, la plupart des principaux moteurs de recherche prennent également en charge ces directives.
Il n’est pas nécessaire d’utiliser la directive allow pour indiquer à un moteur de recherche d’explorer votre site Web, car il le fera par défaut. Toutefois, cette règle est utile dans certaines situations.
Par exemple, vous pouvez définir une directive qui empêche tous les moteurs de recherche d’explorer votre site Web, mais qui autorise un moteur de recherche spécifique, tel que Bing, à le faire. Vous pouvez également utiliser cette directive pour autoriser l’exploration d’un fichier ou d’un répertoire particulier, même si le reste de votre site Web est bloqué.
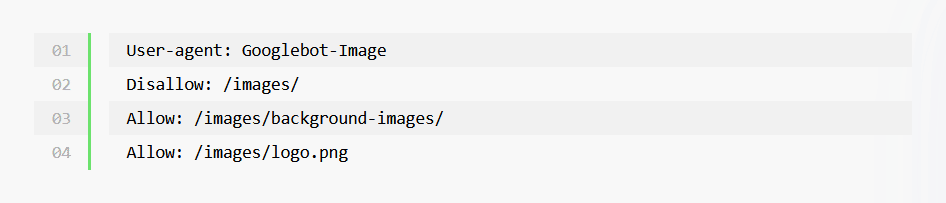
Plusieurs directives peuvent être définies pour le même User agent. Par conséquent, vous pouvez étendre votre fichier robots.txt pour spécifier un grand nombre de directives. Tout dépend de la précision que vous souhaitez donner à ce que les moteurs de recherche peuvent ou ne peuvent pas faire (à savoir qu’il existe une limite au nombre de lignes que vous pouvez ajouter).
La définition de votre sitemap aidera les moteurs de recherche à le localiser plus rapidement. Cela les aidera ensuite à localiser le contenu de votre site Web et à l’indexer. Vous pouvez utiliser la directive Sitemap pour définir plusieurs sitemaps dans votre fichier robots.txt.
Sachez qu’il n’est pas nécessaire de définir un User agent lorsque vous spécifiez l’emplacement de vos sitemaps. Gardez également à l’esprit que votre sitemap doit prendre en charge les règles que vous spécifiez dans votre fichier robots.txt. En d’autres termes, il est inutile de répertorier les pages de votre plan du site à des fins d’exploration si votre fichier robots.txt interdit l’exploration de ces pages.
Un sitemap peut être placé n’importe où dans votre site. En général, les propriétaires de sites Web inscrivent leur sitemap au début ou à la fin du fichier robots.txt.
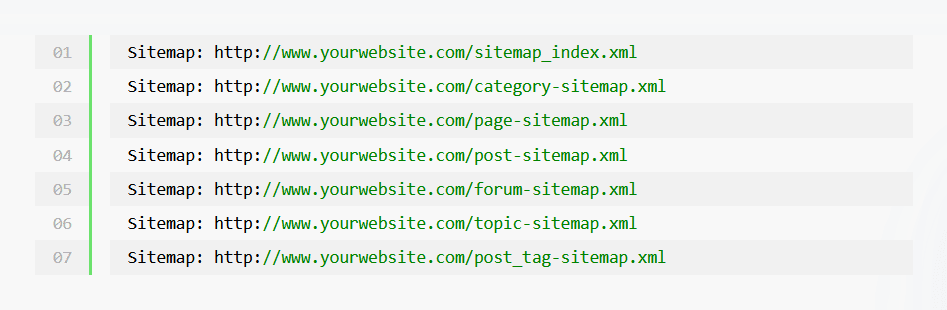
Il est dans votre intérêt de prendre l’habitude de documenter le code dans votre fichier robots.txt. Cela vous aidera à comprendre rapidement les règles que vous avez ajoutées lorsque vous vous y référerez ultérieurement.
Vous pouvez publier des commentaires dans votre fichier robots.txt en utilisant le symbole dièse : #.
L’avantage de la norme d’exclusion des robots est que vous pouvez consulter le fichier robots.txt de n’importe quel site web sur l’internet (à condition qu’il en ait téléchargé un). Il vous suffit de vous rendre sur www.nomdusite.fr/robots.txt.
Si vous consultez le fichier robots.txt de certains sites Web WordPress, vous verrez que les propriétaires des sites Web définissent des règles différentes pour les moteurs de recherche.
Boost Your Web utilise actuellement le code suivant dans son fichier robots.txt :
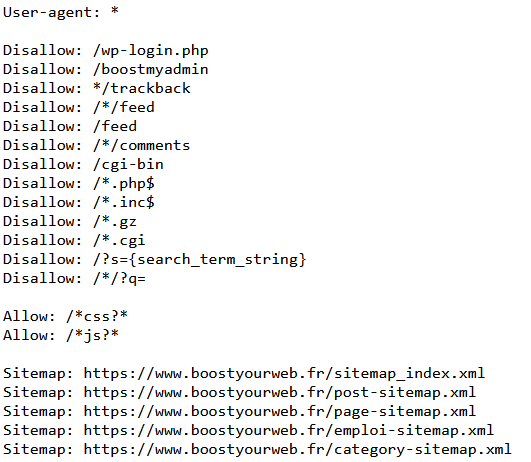
Dans ce fichier robots.txt, on remarque par exemple que la page de connexion est bloquée, de même que celle des commentaires, ainsi que le filtrage : /*?s=
On observe également que les sitemaps y sont renseignés.
Il est toujours recommandé d’empêcher les moteurs de recherche d’explorer les répertoires importants tels que wp-admin, wp-includes, ainsi que vos répertoires de plugins, de thèmes et de cache. Il est préférable de masquer également votre cgi-bin et votre flux RSS.
Selon un article d’AskApache, vous ne devriez jamais utiliser plus de 200 lignes disallow dans votre fichier robots.txt. Malheureusement, l’article ne fournit pas d’éléments permettant de comprendre pourquoi c’est le cas.
En 2006, certains membres de Webmaster World ont signalé avoir vu un message de Google indiquant que le fichier robots.txt ne devait pas comporter plus de 5 000 caractères. Cela correspondrait probablement à environ 200 lignes si l’on suppose une moyenne de 25 caractères par ligne ; c’est probablement de là qu’AskApache a tiré ce chiffre de 200 lignes de disallow.
N’oubliez pas de vérifier la taille de votre fichier robots.txt s’il comporte quelques centaines de lignes de texte. Si le fichier est supérieur à 500 ko, vous devrez réduire la taille du fichier ou vous risquez de vous retrouver avec une règle incomplète appliquée.
La norme d’exclusion des robots est un outil puissant pour indiquer aux moteurs de recherche ce qu’ils doivent explorer et ce qu’ils ne doivent pas explorer. Il est assez facile de comprendre les bases de la création d’un fichier robots.txt, mais si vous devez bloquer une suite d’URL à l’aide de caractères génériques, cela peut devenir un peu complexe.
Veillez donc à utiliser un analyseur de robots.txt pour vous assurer que les règles ont été configurées comme vous le souhaitez. Merkle peut aussi vous aider à le faire !
N’oubliez pas non plus de télécharger le fichier robots.txt à la racine de votre répertoire et d’adapter le code de votre propre fichier robots.txt en conséquence si WordPress a été installé dans un sous-répertoire. Par exemple, si vous avez installé WordPress à l’adresse www.yourwebsite.com/blog/, vous interdirez le chemin /blog/wp-admin/ au lieu de /wp-admin/.
Vous serez peut-être surpris d’apprendre que les moteurs de recherche peuvent toujours répertorier une URL bloquée si d’autres sites Web créent un lien vers cette page.
Vous avez besoin d’aide pour créer votre fichier Robots.txt de façon efficace et pertinente ! Boost Your Web se tient à votre disposition pour vous accompagner !